PinnedNg Wai FoongHow to Fine-tune Stable Diffusion using LoRAPersonalized generated images with custom datasetsFeb 21, 20232Feb 21, 20232
PinnedNg Wai FoonginTowards Data ScienceHow to Fine-tune Stable Diffusion using DreamboothPersonalized generated images with custom styles or objectsNov 15, 20227Nov 15, 20227
Ng Wai FoongBeginner’s Guide to SeamlessM4TThe first, all-in-one, multimodal translation model by Meta AIAug 24, 20231Aug 24, 20231
Ng Wai FoonginPython in Plain EnglishIntroduction to AudioLDM2A unified text-to-audio model for sound effects, human speech and musicAug 23, 2023Aug 23, 2023
Ng Wai FoongBeginner’s Guide to Neural Speaker Diarization with pyannoteAn open-source toolkit written in Python for speaker diarizationAug 8, 20231Aug 8, 20231
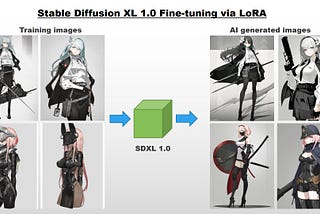
Ng Wai FoongHow to Fine-tune SDXL using LoRAPersonalized text-to-image generation with custom datasetsAug 7, 2023Aug 7, 2023
Ng Wai FoongSplit and Transcribe Audio Files with OpenAI WhisperGeneral purpose method to streamline audio preprocessingAug 1, 2023Aug 1, 2023
Ng Wai FoongSDXL 1.0: The Good, The Bad and The UglyA new era of generative AI for everyoneJul 27, 2023Jul 27, 2023
Ng Wai FoongIntelligent Korean Morpheme Analyzer in PythonUtilizing “kiwipiepy” for Korean natural language processingJul 19, 20232Jul 19, 20232
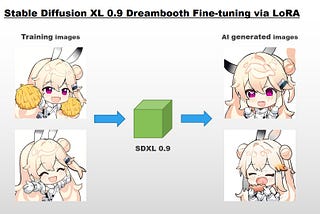
Ng Wai FoongHow to Fine-tune SDXL 0.9 using Dreambooth LoRAPersonalized generated images with custom datasetsJul 13, 20232Jul 13, 20232