Member-only story
Introduction to ControlNet for Stable Diffusion
Better control for text-to-image generation
This tutorial covers a step-by-step guide on text-to-image generation with ControlNet conditioning using the HuggingFace’s diffusers package.
ControlNet is a neural network structure to control diffusion models by adding extra conditions. It provides a way to augment Stable Diffusion with conditional inputs such as scribbles, edge maps, segmentation maps, pose key points, etc during text-to-image generation. As a result, the generated image will be a lot closer to the input image, which is a big improvement over traditional methods such as image-to-image generation.
In addition, a ControlNet model can be trained with small datasets on consumer GPU. Then, the model can be augmented with any pre-trained Stable Diffusion models for text-to-image generation.
The initial release of ControNet came with the following checkpoints:
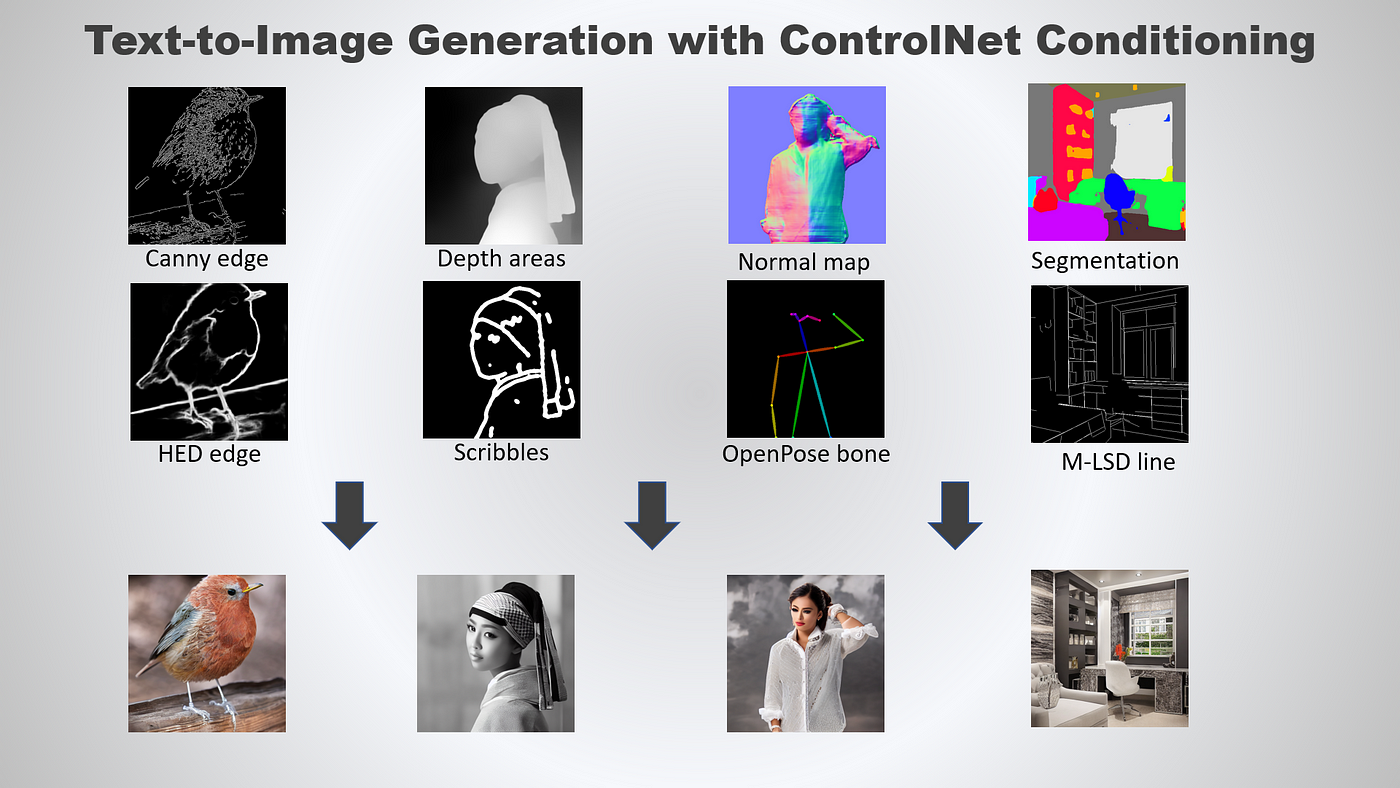
Canny edge— A monochrome image with white edges on a black background.Depth/Shallow areas— A grayscale image with black representing deep areas and white representing shallow areas.Normal map— A normal mapped image.Semantic segmentation map— An ADE20K’s segmentation protocol image.HED edge— A monochrome image with white soft edges on a black background.Scribbles— A hand-drawn monochrome image with white outlines on a black background.OpenPose bone (pose keypoints)— A OpenPose bone image.M-LSD line— A monochrome image composed only of white straight lines on a black background.
Let’s proceed to the next section for the setup and installation.
Setup
It is highly recommended to create a new virtual environment before the package installation.
diffusers
Activate the virtual environment and run the following command to install the stable version of diffusers module:
pip install diffusersControlNet requires
diffusers>=0.14.0
